AI视频画质增强方法攻略:3种技巧修复视频画质

“为什么我的AI生成视频总是不够清晰?”、“那些老电影是如何被修复成4K画质的?”、“普通人也能用AI提升视频画质吗?”这是许多用户都会遇到的画质问题。无论是老旧影像资料、网络传输压缩的视频,还是AI生成的内容,常常面临着模糊、噪点、卡顿等画质问题。视频画质问题的存在,既影响观感体验,也限制了AI视频在专业场景的应用。
不过,好在借助深度学习算法和先进的视频处理工具,AI可以在保留视频内容完整性的前提下,有效提升视频的清晰度。本文将深入解析AI视频画质增强的原理、方法与应用,并结合工具为读者提供实用参考。

一、为什么AI生成的视频画质不够清晰?
为什么算力强大的AI生成的视频依然会出现模糊、闪烁或畸变?主要原因在以下几点:
AI生成视频画质不佳,并非单一因素所致,而是多重技术瓶颈共同作用的结果。理解这些根源,才能更有针对性地进行画质增强。
数据质量与训练局限
AI模型质量如何取决于其训练数据。如果模型使用的训练视频本身分辨率低、压缩率高,那么生成的内容自然难以达到高清标准。许多开源模型为了降低训练成本,使用了大量低质量数据,导致模型在细节还原上“先天不足”。
语义理解的偏差
AI在生成视频时,更多关注的是“物体是什么”(语义),而非“物体表面是什么样”(纹理)。这种重语义、轻细节的生成逻辑,导致了画面在大体结构上正确,但在微观细节上“糊成一团”。
算力与效率的平衡
高画质视频生成需要巨大的计算资源。以4K分辨率为例,其像素数量是1080p的四倍。为了在有限的算力下实现“实时”或“快速”生成,许多AI工具不得不牺牲画质,采用简化算法或降低输出分辨率,最终影响视觉效果。
压缩编码的二次损伤
即便AI生成的原始画面质量尚可,在后续导出、上传、分发过程中,视频平台往往会进行二次压缩。压缩算法会去除“人眼不易察觉”的细节,导致画质进一步劣化,出现色块、锯齿等压缩伪影。
二、核心原理:AI如何“看懂”并“修复”视频?
AI视频画质增强之所以能超越传统方法,核心在于其“学习能力”和“生成能力”。它不再依赖预设的数学公式,而是通过学习海量高清视频,掌握了从低清到高清的映射规律。
1. 深度卷积神经网络(CNN)的特征提取
AI通过多层卷积网络,逐层提取图像特征。浅层网络识别边缘、纹理,深层网络识别物体、语义。当输入一张低分辨率图像时,AI能够像人类视觉系统一样,理解“这是一只眼睛”、“那是一棵树”,从而在重建时依据语义信息填补正确的像素,而非盲目插值。
2. 生成对抗网络(GAN)的“造假”艺术
GAN的引入是画质增强的分水岭。它由生成器和判别器组成:生成器负责将低清图“画”成高清图,判别器负责鉴别这张高清图是真实的还是生成的。两者在博弈中不断进化,最终迫使生成器输出足以乱真的纹理细节。例如,在面对模糊的人脸时,GAN可以根据面部结构,“脑补”出逼真的眉毛、睫毛,这是传统插值算法无法实现的。
3. 时序信息的融合
针对视频的动态特性,现代AI算法引入了光流估计和循环神经网络(RNN)。AI会分析前后帧的信息,利用前一帧的清晰细节来补充当前帧的缺失,或者利用后一帧的运动趋势来校正当前帧的模糊。这种“借力”机制,使得AI能够有效消除视频抖动和伪影,保持画面的流畅与稳定。
三、AI视频画质增强方法技巧
在实际操作中,AI视频画质增强可以采用多种方法和技巧,比如:
方法1:通过提示词增强画质
对于使用AI视频生成工具的用户而言,画质的优劣在很大程度上取决于你输入的提示词。很多人误以为“画质差”是模型的问题,但实际上,精准的提示词通常是能让AI从一开始就输出高质量画面。
为什么提示词能影响画质?
AI视频生成模型本质上是在“理解”你的文字描述,然后从海量训练数据中匹配相应的视觉特征。如果你的提示词中包含了画质相关的关键词,模型会优先调用高画质的训练样本,从而生成更清晰、细节更丰富的视频。
画质增强提示词的黄金公式
一个有效的画质提示词应包含以下3个维度:
维度1:分辨率与清晰度关键词
基础词:4K、8K、超高清、高清
进阶词:超写实、清晰画质、锐利焦点、高度精细
维度2:视觉风格与质感
电影级布光、8k分辨率纹理、专业调色、光线追踪全局光照
维度3:技术规格关键词
60fps(高帧率,让动作更流畅)
hdr(高动态范围,提升光影层次)
实战案例:提示词优化前后对比
优化前的提示词(画质较差):“一只猫在草地上奔跑”
优化后的提示词(画质显著提升):“一只橘猫在阳光明媚的草地上奔跑,4k超高清分辨率,电影级布光,毛发纹理极其细腻,浅景深效果,背景虚化,60fps高帧率,专业级色彩调校”
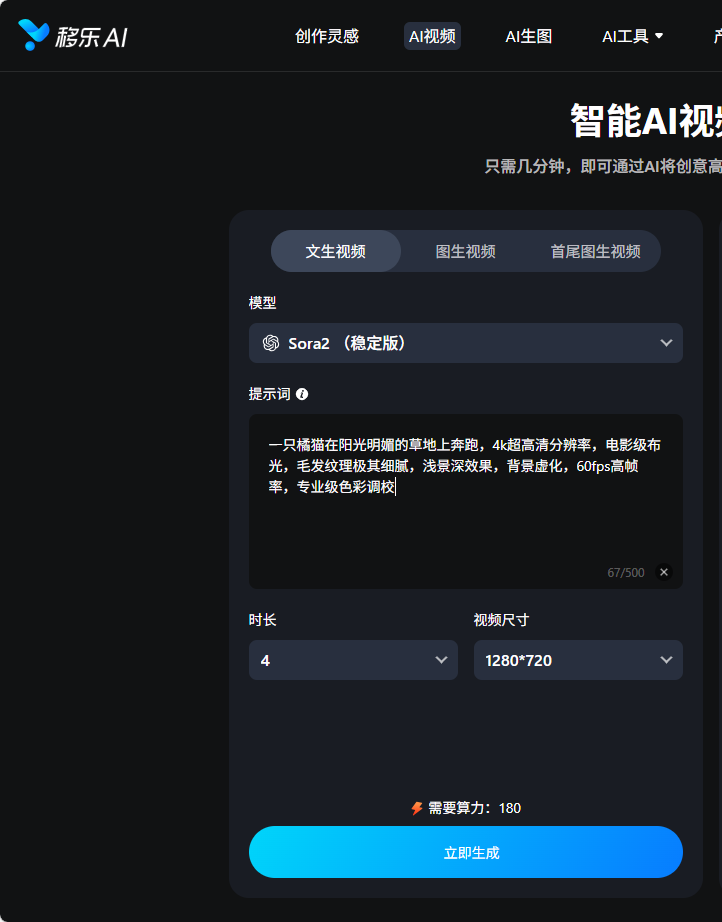
实用技巧
位置靠前原则:将画质关键词放在提示词的前半部分,AI会更重视
组合使用:不要只用一个词,将分辨率、纹理、光影、帧率等关键词组合使用
方法2:AI模型提升视频画质
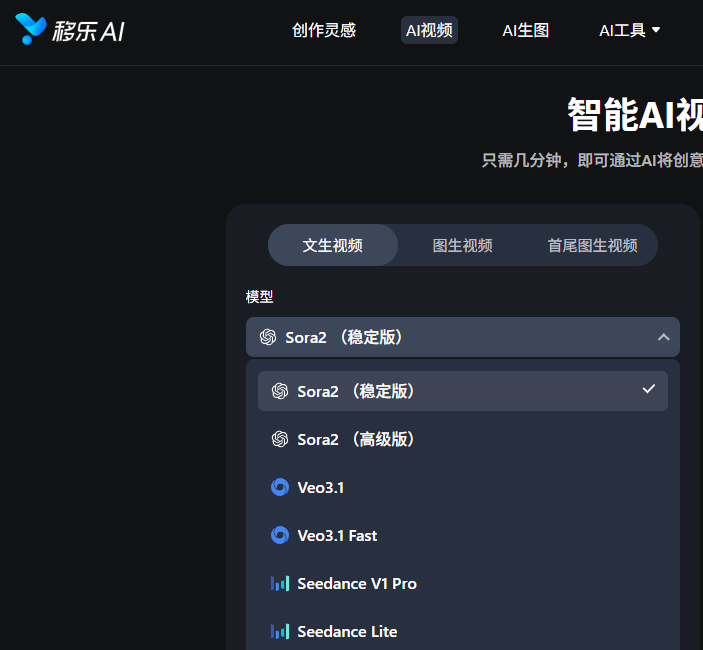
如果说提示词决定了“起点”,那么AI模型的选择则决定了画质的“上限”。市面上涌现出众多视频画质增强模型,各有侧重。顶尖生成模型的选择(Sora与Veo):
OpenAI发布的Sora模型,采用了先进的DiT架构,能够生成长达60秒的高保真视频,其物理模拟的真实度远超前代产品;
Google的Veo模型同样在分辨率和一致性上表现卓越。
对于创作者而言,如果条件允许,直接使用Sora或Veo生成素材,画质将显著优于早期的Gen-2或Pika模型。这些模型原生支持1080P甚至更高分辨率,大幅降低了后期增强的压力。
目前,很多顶尖主流模型都来自国外,对于国内用户而言,可能有一定的使用困难。但对于移乐AI平台,国内用户可直接使用到Sora、Veo模型等国外模型,它已接入了这些模型的接口,所以国内用户可无阻碍的访问使用。
方法3:通过PS(Photoshop)增强画质
除了AI方法,还可以通过Photoshop或类似图像处理软件对视频帧进行画质优化。虽然Photoshop(PS)是图像处理软件,但通过“视频转图像序列”的方式,同样可以实现视频画质的精细增强。这种方法操作难度较高,但能提供像素级的控制能力,适合对画质有极致要求的专业用户。操作步骤详解:
第1步:将视频导出为图像序列
使用视频剪辑软件(如Premiere Pro、DaVinci Resolve)或格式工厂
导出设置:选择PNG或TIFF格式(无损压缩),保持原始分辨率
注意:如果视频时长较长,可先截取关键片段进行处理,避免文件过大
第2步:在PS中批量处理图像
1、打开PS,选择“文件”>“脚本”>“图像处理器”,选择包含图像序列的文件夹
2、设置处理动作:
可录制一个“动作”包含以下步骤:
智能锐化:数量150%,半径1.0-1.5像素
降噪:Camera Raw滤镜中的“细节”面板,调整“减少杂色”
可选:内容识别填充(用于去除水印或瑕疵)
3、选择输出格式(JPEG高质量或PNG),运行批量处理
第3步:将处理后的图像序列合成为视频
使用视频剪辑软件导入图像序列
设置与原视频相同的帧率(如24fps、30fps)
导出时选择高码率,避免二次压缩损失
四、全文小结
以上,就是关于AI视频画质增强方法技巧的全部内容。总的来说,AI视频在很多情况下都有可能生成的不够高清,但是通过正确的方法技巧,这些低分辨率、有噪点等视频通常是可以被修复的。最后,希望本文分享的方法信息对你是有帮助的!

 如何写出专业级AI生图描述词?AI生图效果术语全解析
如何写出专业级AI生图描述词?AI生图效果术语全解析- 如何提升AI视频画面质感?这5个技巧立竿见影
- 好用的文生视频的AI工具有哪些?五款热门软件深度测评
- AI生图哪个工具好用?2026主流AI生图工具盘点(新手向)
- 自己如何制作动漫短视频?7款受欢迎AI视频制作软件深度测评
- AI生图工具,到底强在哪?AI生图从入门到精通
- ai文生视频提示词怎么写?一文分享五大场景模板
- AI生图文生图如何快速上手?从输入到出图的全流程指南
- 图生视频AI工具怎么选?这款宝藏工具,一键生成视频真香!
- 如何用AI文生图软件生成高质量图片?AI文生图新手教程
- 国产ai视频生成器哪个好用?分享6款ai视频生成神器
- 用AI做视频怎么操作的?手把手教你制作AI短视频
- 2026年有哪些好用的AI生图模型?AI生图模型术语解读
- 2026年,文生视频的AI软件有哪些?五款海内外热门工具深度测评
- 零基础学设计:选AI生图还是PS?一文告诉你
- 如何用照片生成视频?三步搞定动态大片(保姆级教程)
- 怎么用图生图模式?AI生图图生图模式用法大全
- 如何用ai生成心仪图片?一文掌握AI生图核心指令术语