如何高效优化AI视频Prompt?本文的Prompt优化技巧很详细

在AI生成领域,AI的生成效果是否精准、符合需求,关键在于如何向AI提供精准的指令——即提示词(Prompt)。通过优化提示词,我们可以有效引导AI生成理想的视频。今天,我们就来系统拆解Prompt优化的底层逻辑,分析一下Prompt常见的误区,并提供Prompt优化技巧,以便用户更好地应用AI视频生成工具。

一、AI 的指令语言:提示词(Prompt)
1、什么是Prompt?
Prompt,中文常译为“提示词”。在AI的工作流程中,Prompt是用户向AI模型输入的指令或描述文本。AI通过解析这些提示词,理解用户的意图并生成相应的内容。
假设,我们要求AI生成一个视频:“一只猫在花园里玩耍”。AI将会通过解析提示词中的关键词(如“猫”,“花园”,“玩耍”)来生成视频。当然,这种简单的描述通常是不足以生成理想的结果,往往需要用户提供更加具体和精确的指令。
影响生成结果的核心因素:
语言的明确性:越清晰的指令,AI越能理解并准确执行。
细节的丰富性:细节越多,生成内容的质量则越高。比如,指定猫的动作、表情、背景环境等。
2、Prompt的类型
根据使用场景和复杂程度,Prompt通常可以分为三类:
简单描述型:这是最常见的提示词类型,简单地描述目标内容即可。如“一只猫在花园里玩”。这种类型虽然能快速生成画面,但缺乏细节和艺术感,不可控因素非常高,生成的结果随机性很强。
结构化/分步骤型:这种类型通常按“主体+场景+动作+风格”等模块组织描述,将需要描述的内容分解成多步。这种方式逻辑很清晰,便于AI理解复杂指令。
条件约束型:在描述中加入否定词或限定条件,如“视频中不出现人类”“避免使用卡通风格”“镜头仅在水平方向移动”。适合需要排除特定元素的专业创作。
二、为什么提示词过于简单/复杂都不行?
在使用AI时,很多用户常常会遇到两种极端:提示词过于简单或过于复杂。两者都容易导致生成结果的不理想。
1、用户常见误区
误区1:Prompt太笼统 → 输出模糊
很多用户习惯用日常口语与AI交流,比如用AI生成一条视频,提示词如:“拍一个好看的视频”。对于AI来说,“好看”是一个极其抽象的概念,是色彩鲜艳好看,还是构图极简好看?这种模糊指令会让AI胡乱定位,最终只能随机生成一个平庸的画面。
误区2:Prompt过度复杂 →容易“跑题”
当提示词超过一定长度,AI的注意力机制可能忽略关键信息,反而抓住某个次要细节放大。所以说,如果用户输入的信息过载,AI容易“顾此失彼”,甚至抓不住重点,导致生成的画面逻辑混乱,元素堆砌严重。
2、误区分区
让我们通过几个具体案例,看看AI是如何“误解”我们的:
太抽象:缺乏具象锚点
“一只猫在玩”。这个描述里,AI不知道“玩”的具体动作定义。是玩毛线球?玩逗猫棒?还是玩自己的尾巴?由于缺乏具体指引,AI只能基于概率随机生成,可能导致猫的动作呆板,或者在空中莫名其妙地飞舞。
缺要素:没有镜头语言
很多人写Prompt只关注“拍什么”,却从不告诉AI“怎么拍”。这就像让摄影师只拍“一个人走路”,却不说用特写还是远景、固定机位还是跟拍,那么视频生成的结果就会像监控录像,毫无美感。
逻辑冲突:物理规律崩坏
虽然AI擅长幻想,但物理逻辑的严重冲突会导致模型崩溃。比如:“一个在水下骑自行车的人,背景是燃烧的火山”。AI就容易陷入矛盾,因为它的训练数据里没有这种反物理场景,只能强行生成,结果就是画面扭曲、闪烁。
3、AI的理解方式:关键词权重与语义关联
想要写出好Prompt,就要先要理解AI怎么“读”你的话。
AI视频模型(如Sora2等)基于扩散模型和Transformer架构工作。当你输入一段文字,它会做三件事:
- 关键词提取:识别出“猫”“玩”“花园”等核心名词
- 权重分配:根据词的位置和重复程度分配注意力(句首的词通常权重更高)
- 语义关联:将你的描述与训练数据中的数亿个图文对进行匹配,找到最相似的视觉特征
这就是为什么量化描述和结构顺序非常重要,它们会直接引导AI的注意力焦点。
三、Prompt优化的核心公式
经过大量实战验证,一个高质量的AI视频Prompt应该包含五个核心要素。这些要素能够有效地提升生成结果的质量,使AI能够更准确地理解并执行。
公式:
主体描述 + 具体动作 + 环境氛围 + 镜头语言 + 风格修饰
主体描述:主体是视频的主角,必须清晰明确,避免模糊。例如:“一只白色的猫”比“猫”更清晰。
具体动作:视频的核心是“动”,必须明确动作的幅度和方式。可以选择动词+副词,或者描述动作的连续性。如:“缓缓抬起头,深吸一口气,目光渐渐地望向远方…”
环境氛围:环境决定了故事的背景和基调。用户需要描述光线、天气、时间段以及背景细节。例如“清晨薄雾笼罩的竹林,阳光透过竹叶洒下斑驳光影,远处有鸟鸣回声”。
镜头语言:这是视频生成的灵魂所在,它决定了画面的表达方式。五种基础运镜:
- 推镜头:从远景推向主体,强化焦点
- 拉镜头:从主体拉远,展现场景全貌
- 摇镜头:以主体为中心水平旋转,展示环境
- 跟镜头:跟随主体移动,保持相对位置
- 环绕运镜:旋转拍摄,强调主体地位
例如:“镜头从远景缓慢推近至女子面部特写,保持浅景深,背景虚化”
风格修饰:设定画面风格和质感,可以帮助调定生成的视觉风格。例如:“赛博朋克风格,霓虹灯光以紫色和青色为主,画面略带噪点,电影质感,4K超清”。
Prompt场景逐项拆解
为了让大家更直观地理解,我们来进行三组对比演练。
【场景1:人物特写】
错误示范:“一个漂亮的女人。”
太笼统。AI可能生成卡通脸、模糊的五官,或者背景杂乱无章。
优化示范:“一位齐肩短发的年轻女性,特写镜头,眼神清澈,黑色的长发随风轻抚,背景是模糊的春日花园,柔和的自然光打在脸上,8k分辨率,极其逼真。”
【场景2:动物动态】
错误示范“一只狗在跑。”
动作僵硬,缺乏速度感,可能像是在跑步机上跑。
优化示范:“一只金毛猎犬在金色的麦田中全速奔跑,耳朵随风飞扬,阳光洒在它的毛发上闪闪发光,镜头跟随拍摄,捕捉奔跑的瞬间,慢动作,高帧率。”
【场景3:科幻场景】
错误示范:“未来的城市。”
生成的结果可能是简单的楼房模型,缺乏科技感和细节。
优化示范:“赛博朋克风格的未来大都市,高耸入云的摩天大楼,空中穿梭的飞行汽车,巨大的全息广告牌闪烁着蓝色和粉色的光芒,无人机视角俯瞰城市,夜景,史诗般的宏大场面。”
四、实战演练:以移乐AI为例
理论学了不少,如何在具体工具中落地?这里以移乐AI为例,展示从Prompt到成片的完整流程。
移乐AI是国内用户无门槛体验Sora2等前沿模型的集成平台,它接入了Sora2、Veo等多种主流视频模型,方便用户多模型切换测试,并且还提供文生视频、图生视频、首尾图生视频三种创作模式,用户可任意挑选适合的创作模式。
假设我们想生成一段“古风少女抚琴”的视频。
第1步:构建完整的Prompt
按照公式:
主体:一位身穿淡青色汉服的古代少女,发髻高挽,插着玉簪。
动作:纤细的手指轻轻拨弄古琴琴弦,神情专注。
环境:幽静的竹林深处,阳光透过竹叶洒下斑驳光影,石桌上放着袅袅升香的香炉。
镜头:中景推近,侧脸特写。
风格:中国水墨画风格,唯美意境,4k高清。
第2步:选择模型输入提示词
打开移乐AI的文生视频界面,并选择Sora2模型,然后将上述要素串联输入提示词框架中:
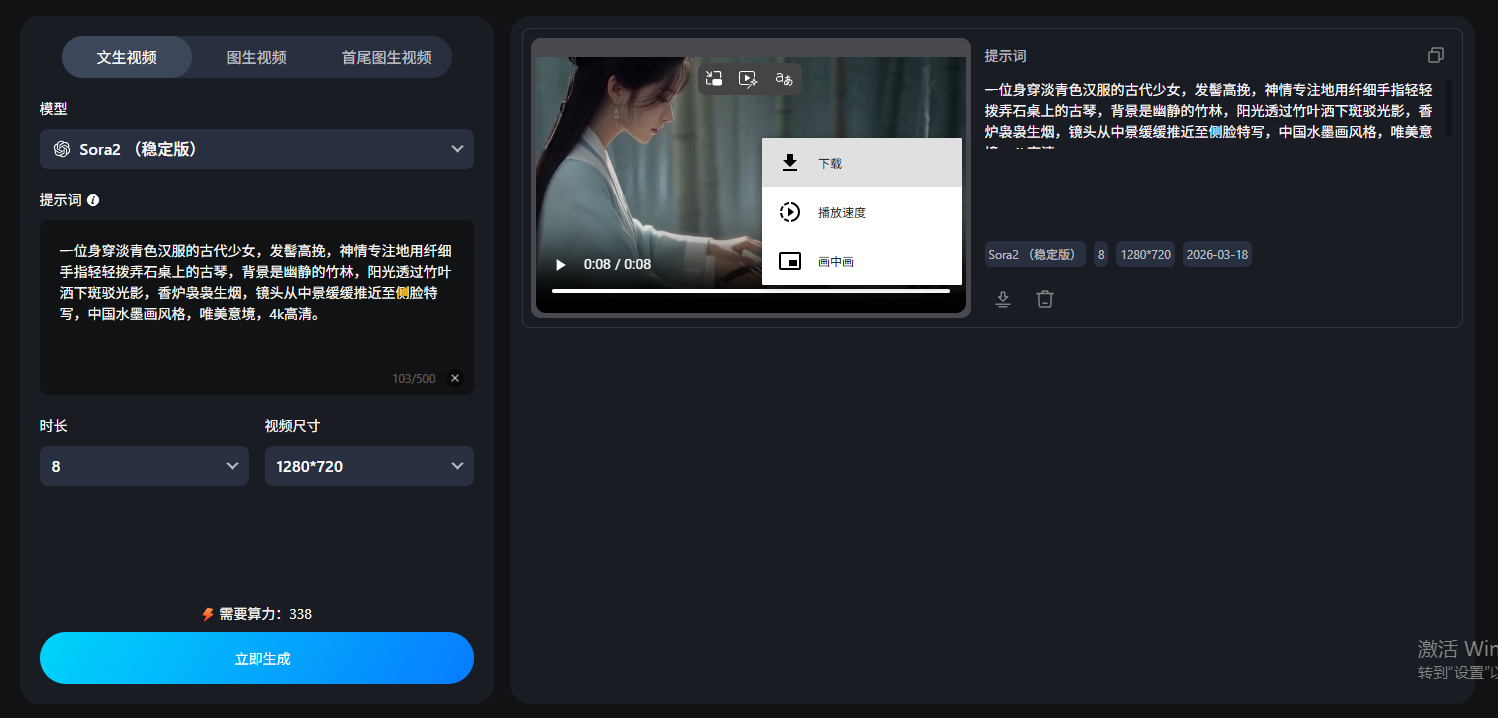
“一位身穿淡青色汉服的古代少女,发髻高挽,神情专注地用纤细手指轻轻拨弄石桌上的古琴,背景是幽静的竹林,阳光透过竹叶洒下斑驳光影,香炉袅袅生烟,镜头从中景缓缓推近至侧脸特写,中国水墨画风格,唯美意境,4k高清。”
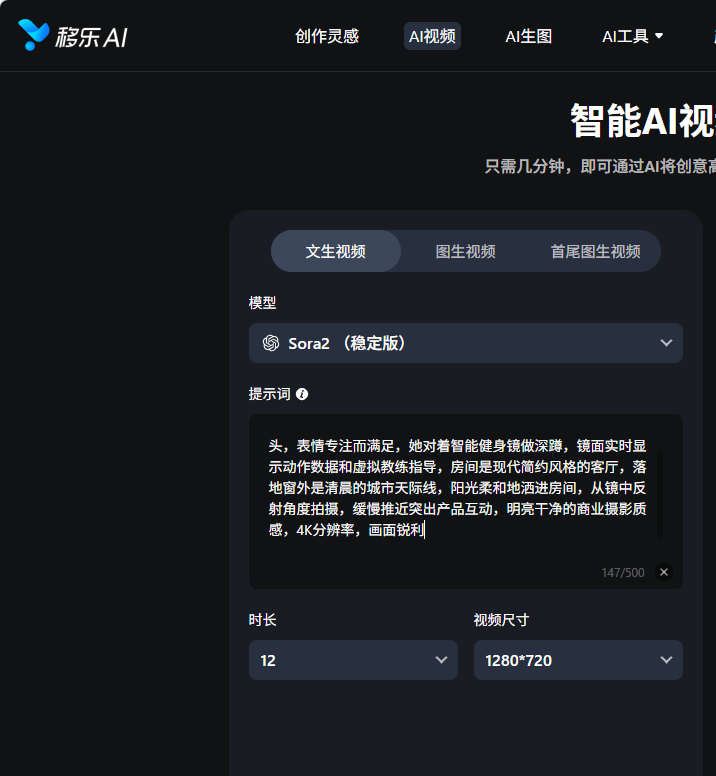
第3步:点击生成并等待
点击“立即生成”,等待1-3分钟。预览生成效果,满意则下载,不满意可修改Prompt重新生成。
五、全文小结
优化提示词(Prompt)是AI生成内容中的关键步骤。无论是在创意视频、图像还是其他形式的AI生成内容中,精准的提示词都是确保高质量输出的基础。希望本文的分析和实战演练,能够帮助你更好地掌握Prompt优化技巧。

 AI视频生成为什么总翻车?六大误区与破解思路
AI视频生成为什么总翻车?六大误区与破解思路- AI生图到底是怎么“画”出图像的?一文讲清背后的逻辑
- 如何写出专业级AI生图描述词?AI生图效果术语全解析
- 如何提升AI视频画面质感?这5个技巧立竿见影
- 好用的文生视频的AI工具有哪些?五款热门软件深度测评
- AI生图哪个工具好用?2026主流AI生图工具盘点(新手向)
- 自己如何制作动漫短视频?7款受欢迎AI视频制作软件深度测评
- AI生图工具,到底强在哪?AI生图从入门到精通
- ai文生视频提示词怎么写?一文分享五大场景模板
- AI生图文生图如何快速上手?从输入到出图的全流程指南
- 图生视频AI工具怎么选?这款宝藏工具,一键生成视频真香!
- 如何用AI文生图软件生成高质量图片?AI文生图新手教程
- 国产ai视频生成器哪个好用?分享6款ai视频生成神器
- 用AI做视频怎么操作的?手把手教你制作AI短视频
- 2026年有哪些好用的AI生图模型?AI生图模型术语解读
- 2026年,文生视频的AI软件有哪些?五款海内外热门工具深度测评
- 零基础学设计:选AI生图还是PS?一文告诉你
- 如何用照片生成视频?三步搞定动态大片(保姆级教程)